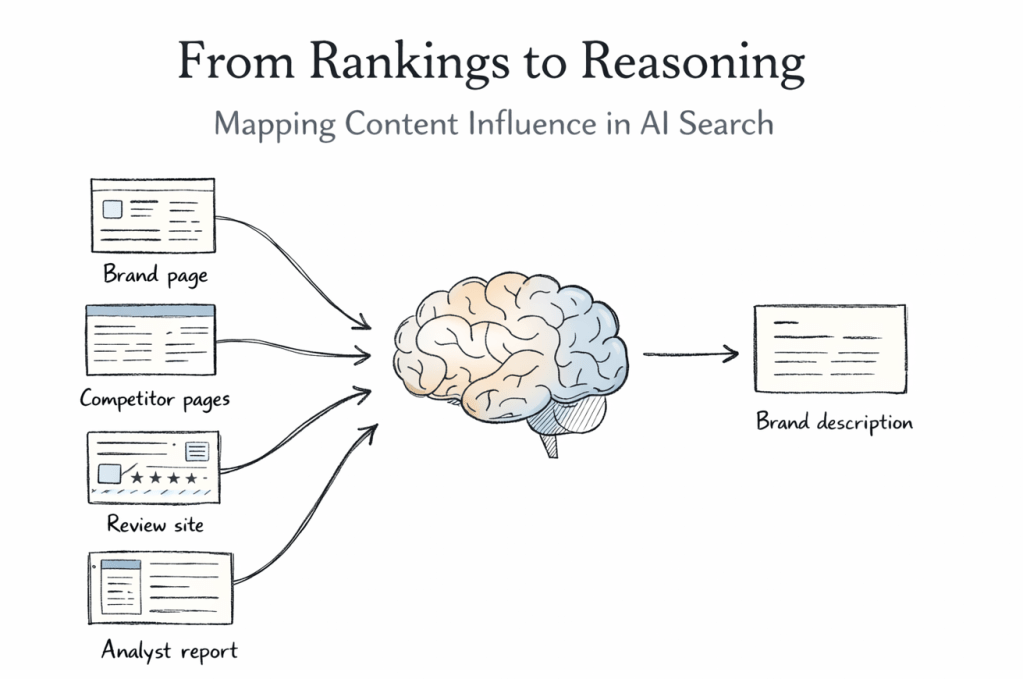
For more than a decade, search visibility had a simple definition – if your page ranked on page one, you were visible and if it did not, you were not. Entire teams, budgets, and strategies were built around that assumption and for a long time it held.
AI search quietly breaks that model.
Today, when buyers ask AI systems for recommendations, comparisons, or explanations, the response they receive is not something they can scan, compare, or interpret on their own terms. It is a single, synthesized narrative that already contains judgment and framing. By the time a buyer visits a website or speaks to sales, that framing has often settled into place.
That shift raises a harder question than ranking ever did – why did the AI describe your brand the way it did?
Not whether you were mentioned or cited but why the AI chose specific language, positioning, and comparisons when talking about you.
Traditional SEO tools cannot answer this and citation tracking does not come close. In many cases, the content that shapes an AI’s explanation is never credited at all.
This gap between influence and visibility is what led us to this experiment.
We wanted to understand what content actually influences how AI systems describe a brand for a given query and whether that influence could be measured, explained, and traced back to specific sources rather than treated as opaque model behavior.
How We Set Up The Experiment
The goal of this experiment was to understand how an AI constructs a description of a brand when answering a category level query.
To keep the setup controlled, we focused on a single AI system and used ChatGPT as the response surface for this example. The behaviour we were examining is not specific to one model but it reflects how large language models synthesize meaning across sources when responding to buyer style questions.
Further, we chose one of the most competitive segments in B2B software – customer engagement platforms and rather than using abstract prompts, we worked with queries that closely mirror how buyers and practitioners actually ask these questions.
The core queries used in the experiment were –
- Best customer engagement platforms
- Customer engagement platform for B2B SaaS
- Customer engagement software for mobile apps
- Cross channel customer engagement platforms
Each of these queries was further expanded into multiple prompt variations to account for differences in phrasing and intent but all mapped back to the same underlying question – how does the AI describe the category and position brands within it?
This gave us a realistic set of AI responses to analyse before moving into the influence mapping itself.
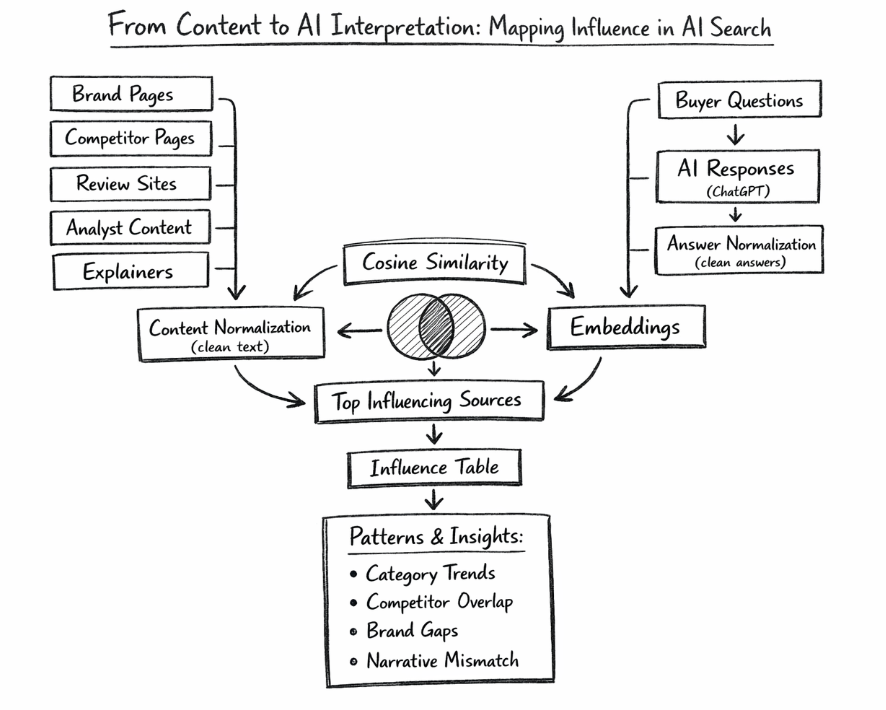
With the AI responses in place, the next step was to define the universe of content that could plausibly shape those responses.
Step 1: Build The Content Universe
You need a representative set of sources that could plausibly influence how the model talks about the category and your brand. That includes –
- Brand owned pages (homepage, product, pricing, category, use case pages)
- Direct competitor positioning pages
- Review and marketplace pages (G2, Gartner Peer Insights, Capterra, etc.)
- Analyst and category definition pages
- Neutral explainers and comparisons
Tools You Can Use
- Google Sheets (indexing URLs)
- A crawler or scraper (Apify, Screaming Frog, simple requests scripts)
- A clean text extractor (Readability style parsing, Trafilatura, Mercury parser)
- Manual copy paste for a small set, if you are starting
Data Setup
Create a Google Sheet called content_sources with these columns –
- source_id (unique, stable)
- source_type (owned, competitor, review, analyst, explainer)
- url
- title
- meta_description
- h1
- excerpt_1
- excerpt_2
- clean_text (the concatenated, normalized field)
- last_fetched_at

A Practical Tip – Keep it consistent and short enough to be comparable. A practical approach is – clean_text = title + meta_description + h1 + excerpt_1 + excerpt_2
Avoid pulling entire pages early as you only want representative meaning – not every paragraph.
Step 2: Collect AI Answers As Narratives
Instead of asking one prompt per query, collect multiple phrasing variants that represent how real users ask such as
- best customer engagement platforms
- <Your Brand Name> alternatives
- customer engagement platform for B2B SaaS
For each intent, generate 5 to 7 prompt variants and then capture the responses from each AI system you care about.
Tools You Can Use
- ChatGPT, Gemini, Perplexity
- A spreadsheet to store prompt answer pairs
- Optional – a lightweight script using each platform API later once you scale
Data Setup
Create a sheet called ai_responses with following columns –
- response_id (unique)
- platform (chatgpt, gemini, perplexity)
- query_intent (best platforms, alternatives, etc.)
- prompt_variant
- raw_response_text
- clean_answer_text (optional, but recommended)
- captured_at
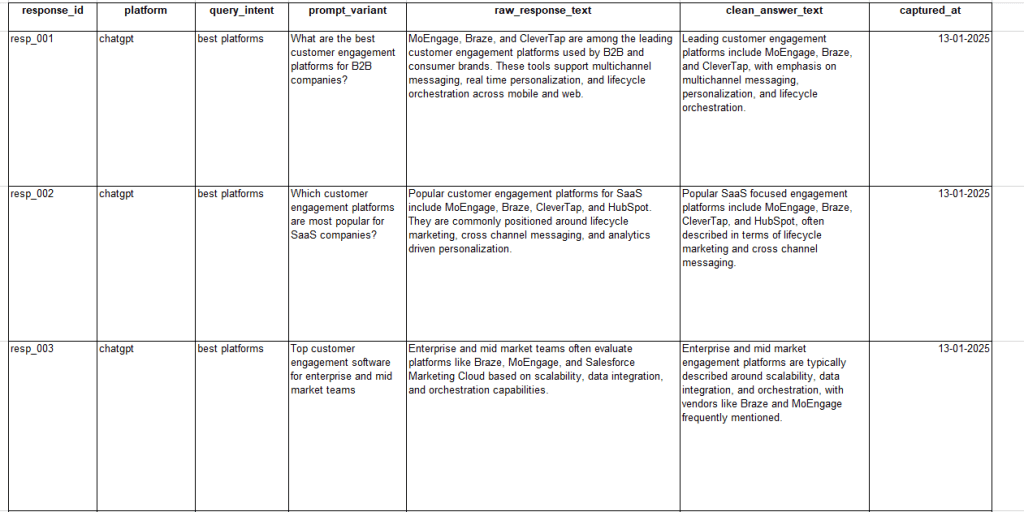
A Practical Tip – Use clean_answer_text to remove obvious boilerplate, disclaimers, and formatting noise, while preserving meaning.
Step 3: Generate Embeddings For Sources And Answers
Keyword overlap breaks here because models usually paraphrase. Making use of embeddings let you compare meaning instead.
You will generate embeddings for –
- each content_sources.clean_text
- each ai_responses.clean_answer_text
Tools You Can Use
- OpenAI embeddings API
- Any embedding provider, as long as you stay consistent
- Python for batch processing
- Optional: Make or Zapier for automation
How Embeddings Look
An embedding is a vector of floats, typically length 1536 or 3072 depending on model. You will not interpret individual dimensions but you will need them for calculating the similarity.
For example,
- The embedding would look like this – [0.0123, -0.0441, 0.0872, … ]
- len(embedding): 1536
Step 4: Compute Cosine Similarity As Influence Proxy
For each AI answer embedding, compute cosine similarity against every source embedding and then keep only the top N sources per answer. That is your influence trace.
Tools You Can Use
- Python with NumPy
- Google Colab for a clean notebook experience
- Optional – a vector database for scale later
Practical Implementation
Below is a minimal end to end Python workflow. It assumes you have two CSV exports from your sheets –
- content_sources.csv containing source_id and clean_text
- ai_responses.csv containing response_id and clean_answer_text
1) Install Dependencies
pip install pandas numpy openai2) Create Embeddings And Write Them To Files
import os
import time
import pandas as pd
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
EMBEDDING_MODEL = "text-embedding-3-small"
def normalize_text(x, max_chars: int = 12000) -> str:
# Handles NaN, None, numbers safely
if x is None:
return ""
if isinstance(x, float) and pd.isna(x):
return ""
s = str(x).strip()
if not s:
return ""
# Simple safety cap. Token based truncation can be added later.
return s[:max_chars]
def embed_batch(texts: list[str], max_retries: int = 5) -> list[list[float]]:
# OpenAI embeddings supports list input
for attempt in range(max_retries):
try:
resp = client.embeddings.create(model=EMBEDDING_MODEL, input=texts)
return [item.embedding for item in resp.data]
except Exception:
if attempt == max_retries - 1:
raise
time.sleep(2 ** attempt)
def add_embeddings(df: pd.DataFrame, text_col: str, batch_size: int = 64) -> pd.DataFrame:
df = df.copy()
df[text_col] = df[text_col].apply(normalize_text)
texts = df[text_col].tolist()
embeddings: list[list[float]] = []
for i in range(0, len(texts), batch_size):
batch = texts[i : i + batch_size]
embeddings.extend(embed_batch(batch))
df["embedding"] = embeddings
return df
# Expected columns:
# content_sources.csv: source_id, clean_text
# ai_responses.csv: response_id, clean_answer_text
content = pd.read_csv("content_sources.csv")
answers = pd.read_csv("ai_responses.csv")
content = add_embeddings(content, "clean_text")
answers = add_embeddings(answers, "clean_answer_text")
content.to_json("content_sources_with_embeddings.jsonl", orient="records", lines=True)
answers.to_json("ai_responses_with_embeddings.jsonl", orient="records", lines=True)
print("Saved embeddings JSONL files:")
print("content_sources_with_embeddings.jsonl")
print("ai_responses_with_embeddings.jsonl")
Example of embedding record you will see –
{
“source_id”: “src_013”,
“clean_text”: “Choose a cross channel marketing hub that amplifies your customer obsession strategy …”,
“embedding”: [0.0123, -0.0441, 0.0872]
}
The actual embedding array will be much longer.
3) Compute Cosine Similarity And Keep Top Influencers
import json
import numpy as np
import pandas as pd
def cosine_similarity(a: np.ndarray, b: np.ndarray) -> float:
if a.size == 0 or b.size == 0:
return 0.0
denom = float(np.linalg.norm(a) * np.linalg.norm(b))
if denom == 0.0:
return 0.0
return float(np.dot(a, b) / denom)
# Load JSONL files
content_rows = []
with open("content_sources_with_embeddings.jsonl", "r", encoding="utf-8") as f:
for line in f:
content_rows.append(json.loads(line))
answer_rows = []
with open("ai_responses_with_embeddings.jsonl", "r", encoding="utf-8") as f:
for line in f:
answer_rows.append(json.loads(line))
content_df = pd.DataFrame(content_rows)
answers_df = pd.DataFrame(answer_rows)
# Ensure embeddings exist and are lists
content_df["embedding"] = content_df["embedding"].apply(lambda x: x if isinstance(x, list) else [])
answers_df["embedding"] = answers_df["embedding"].apply(lambda x: x if isinstance(x, list) else [])
content_vecs = [np.array(x, dtype=np.float32) for x in content_df["embedding"]]
answer_vecs = [np.array(x, dtype=np.float32) for x in answers_df["embedding"]]
TOP_K = min(8, len(content_vecs))
results = []
for i, a_vec in enumerate(answer_vecs):
sims = []
for j, c_vec in enumerate(content_vecs):
score = cosine_similarity(a_vec, c_vec)
sims.append((j, score))
sims.sort(key=lambda x: x[1], reverse=True)
top = sims[:TOP_K]
for rank, (j, score) in enumerate(top, start=1):
results.append(
{
"response_id": answers_df.loc[i, "response_id"],
"source_id": content_df.loc[j, "source_id"],
"similarity": round(score, 6),
"influence_rank": rank,
}
)
influence_df = pd.DataFrame(results)
influence_df.to_csv("influence_match.csv", index=False)
print("Wrote influence_match.csv with rows:", len(influence_df))
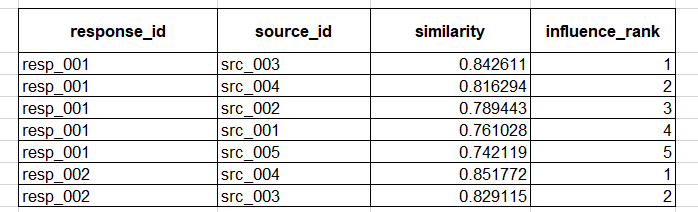
Step 5: Build The Influence Table And Inspect Patterns
Your influence_match table is your evidence layer. It should be empty in the product until computed.
Columns:
- response_id
- source_id
- similarity
- influence_rank
Then join it back to your source metadata for interpretation –
- source type
- competitor vs owned vs review
- platform where the answer came from
What The Results Tend To Reveal
In our run, we observed the following things –
- Category content dominates influence – Category explainers and comparisons often sit at the top of similarity rankings because they define the shared language of the space.
- Competitor positioning leaks into brand perception – Competitor pages influence the answer even when the question is about one brand because the model synthesizes across comparable product narratives.
- Brand content is present but not always the anchor – Your pages may show up in the top influencers but not as the dominant framing source, especially if your category language is weaker than the markets default vocabulary.
- Citations and influence are decoupled – Some of the most semantically aligned sources are never cited which is why citation tracking alone will mislead you.
Closing Thoughts
AI search is changing how meaning is formed, not just how information is retrieved. Brands are no longer evaluated page by page – they are interpreted through category language, competitor positioning and third party explanations that sit outside direct control.
With this exercise, you can move beyond guessing and start understanding which content shapes how AI systems talk about your brand, where that influence comes from, and how it diverges from what you expect.
That clarity is what makes AI visibility something you can reason about and not just react to.
Frequently Asked Questions
1. How does AI search decide how to describe a brand?
AI systems do not rely on a single source – they synthesize meaning across brand content, competitor pages, review platforms, analyst definitions, and category explainers. The final description reflects repeated semantic patterns rather than rankings or citations alone.
2. Why does my brand appear in AI answers but with the wrong positioning?
This usually happens when category or competitor content has stronger semantic influence than brand owned content. AI models often borrow language from dominant narratives in the category, even when the brand is mentioned correctly.
3. Are citations a reliable way to measure AI visibility ?
No. Citations show what the AI chose to credit, not what actually influenced the response. Many highly influential sources shape wording and framing without being cited at all.
4. What is content influence in AI search?
Content influence refers to how closely a piece of content aligns with the language and concepts used by an AI when generating answers. It measures semantic impact rather than surface level visibility like rankings or mentions.
5. How can I measure which content influences AI answers about my brand?
You can compare AI responses and content sources using embeddings and similarity scoring. This allows you to trace which pages most closely align with how the AI constructs its answers and positions brands.
6. How should brands adapt their SEO strategy for AI search?
Brands need to move beyond keyword optimization and focus on shaping category language. This means investing in clear positioning, consistent explanations, and content that reinforces how the category itself should be described.





Leave a comment