
A founder I spoke with recently typed a simple question into ChatGPT: “What does our product <xyz> do?”
The answer came back smooth and confident – but not entirely correct. A retired feature was positioned as the core offering, the ICP was twisted and a competitor’s differentiator had somehow been added into their narrative.
He laughed at first but then suddenly paused. It quickly dawned on him that if AI describes his product this way, his buyers might be seeing the same thing. And now he was worried!
This is the reality for many similar founders and marketing operators – for the first time their brand can be misrepresented at scale before anyone lands on their website, sees demo, or speaks to their team. And, the challenge is they cannot accurately trace where it is coming from.
It feels like being reviewed by someone you have never met based on a version of your product that no longer exists. This is the new reality of AI-mediated discovery and if you do not shape it, it shapes you.
The Wrong Diagnosis Most Teams Make
The instinctive explanation is always the same – “The model hallucinated.” It is a convenient label because hallucination sounds like a technical problem outside your control.
But, what rarely gets discussed is the deeper truth – most SaaS companies have weak, inconsistent, or outdated signals scattered across the public web.
LLMs do not hallucinate out of thin air – they reconstruct based on whatever fragments they find and amplify the patterns they trust most. If the story of your product is fragmented, the model stitches those pieces together the best it can.
Is the result sometimes inaccurate? Yes!
Is it random? Not really!
The output often reflects the collective footprint your company has left across the internet – not your homepage, not your pitch deck, but the messy ecosystem of signals outside your control.
This is why two companies with similar product scope often get described very differently – the one with a denser signal trail tends to have its narrative represented more accurately.

A Perspective We Rarely Acknowledge
Most SaaS teams still behave as if their website is the official source of truth. That used to be a safe assumption when Google indexed your site, ranked it, and users saw the version of you that you curated.
But LLMs do not work like crawlers – they do not recheck your website weekly and they do not prioritize your copy because you are the owner.
They construct meaning the way humans do – by absorbing clusters of information, triangulating signals and trusting sources that appear more objective or widely repeated.
This is why –
- A three year old blog review on a reputable domain can outweigh your latest positioning
- A Reddit thread with 60 upvotes can shape your category narrative
- A miscategorized G2 listing can echo through multiple model summaries
- A competitor’s description of your product can become your truth inside the model
Your brand becomes a reconstruction, not a retrieval. And reconstruction rewards consistency, not intention.
Why LLMs Misdescribe Products: The Real Reasons
The Internet Does Not Have Enough Material To Work With
A pattern I keep seeing among early stage teams is they assume their product is clear because they have talked about it enough.
But the public web has almost nothing – no reviews, no long conversations, no third-party mentions, no comparisons. In that vacuum, the model fills space with whatever is closest in shape.
You know when someone tries to explain a city they have never visited? They start using clichés because they have no real experience to draw from.
AI does the same.
A study published in Tencent AI Lab in May 2025 pointed out that hallucinations increases sharply when the model lacks strong contextual grounding or reliable input. In other words, the model guesses the most when the world has not said enough about you.
For SaaS brands, this is common – many products have rich internal narratives but very thin external footprints. And LLMs only see the latter.
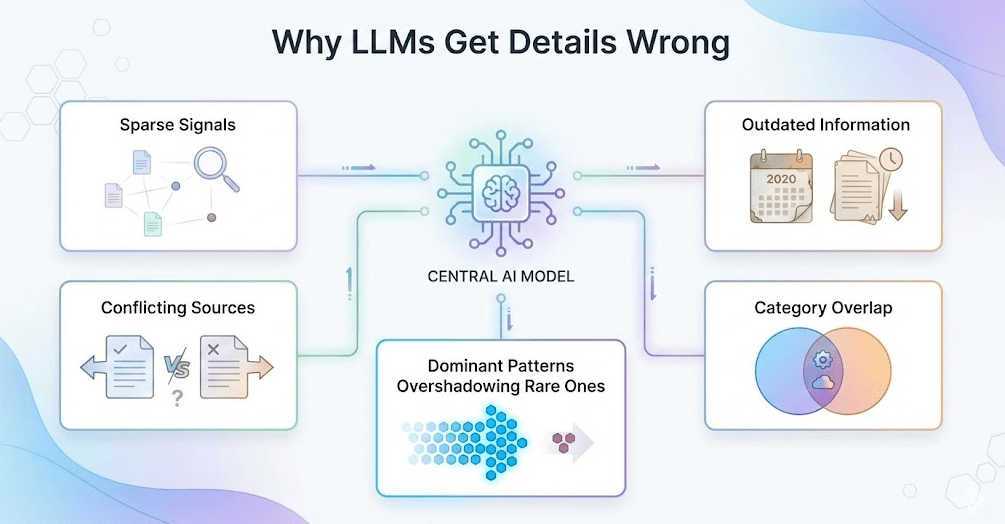
The Old Version of You Still Dominates The Web
One of the strangest parts of AI summaries is how they drag ghosts forward.
A feature you deprecated quietly two years ago suddenly appears as your “primary differentiator”.
A pivot you made never shows up because the internet never rewrote your story and in many cases, your old G2 description or a 2020 TechCrunch blurb becomes the anchor the model believes most.
A paper published at University of North Carolina have highlighted the challenge of knowledge conflict in LLMs showing how models often struggle when internal parametric memory and retrieved external context contain inconsistencies or outdated information leading to factual inaccuracies in the output.
It means the version of you that the internet remembers can overpower the version of you that actually exists. And that is a scary place to be.
You Blend Into Your Category More Than You Think
If you operate in CRM, CDP, customer engagement, email automation, or any category with semantic overlap, you know this problem already – AI models sometimes describe you like a mash-up of your nearest competitors.
It is not intentional nor malicious – it’s just math. Research shows that when category boundaries or input meaning is ambiguous, LLMs default to dominant patterns.
The model compresses complexity into clusters and if your narrative is not distinct enough, you get absorbed into the nearest dominant cluster. And this is why you might open an AI answer and see two sentences that feel exactly like your competitor wrote them.
High Trust Sources Overshadow Your Own Narrative
A strange but consistent reality is that your website is not the most important input for AI. High authority sources shape the model’s worldview far more.
If Gartner, G2, a popular Medium article, an analyst report, or a Reddit thread has described your product – rightly or wrongly – the model treats those signals as high-confidence anchors.
This is great when external descriptions are correct but is devastating when they are outdated or flawed.
And because you do not control these sources, it becomes very easy for the world’s perception of your product to drift away from your internal truth.
If Your Category Is Vague, The Model Forces You Into One It Understands
SaaS lives in a world where categories blur – a messaging tool becomes an engagement platform, an engagement platform becomes a CRM extension and a CRM extension becomes an analytics layer.
But LLMs like solidity and hence, the moment they encounter ambiguity, they resolve it by placing you into the nearest, best-known category – even if that is not where you belong.
Several recent studies show that when LLMs face ambiguous or overlapping categories, they tend to rely on dominant internal patterns rather than the specific details of the input. This often leads to blended or oversimplified descriptions for products in crowded SaaS categories. (Source)
What this means is that if your product does not clearly fit into any defined categories, the model will rewrite you to fit one of them.
A Small Reality Check
Multiple studies now show that generative AI is entering the earliest stages of B2B discovery. Forrester reports that 89% of enterprise buyers have adopted generative AI tools as part of their research workflow, and other surveys show growing use of AI for market research and vendor evaluation.
What this means is simple but uncomfortable – the first story prospects see about your product is no longer the one you wrote but what someone else told.
So How Do You Fix It Before Buyers See It?
Here’s a 5 step framework that you can follow to improve AI accuracy for your product –
Step 1 – Start by Understanding The Current “AI Version” Of Your Product
Most teams have never asked AI the uncomfortable questions –
- Who are we?
- What do we do?
- What are our strengths and weaknesses?
- Who do we compete with?
And then compared those answers across ChatGPT, Gemini, Perplexity, Claude, Grok, and others. You cannot fix the inaccuracies you have not seen and you will be surprised by how much drift has already happened once you check the responses.
Sometimes models consistently misdescribe your ICP, sometimes they overemphasize legacy features and sometimes they classify you in a category you never intended to be in. The output is a mirror of your digital footprint – distorted in some places and accurate in others.
Your job is to note down those distortions before prospects rely on them.
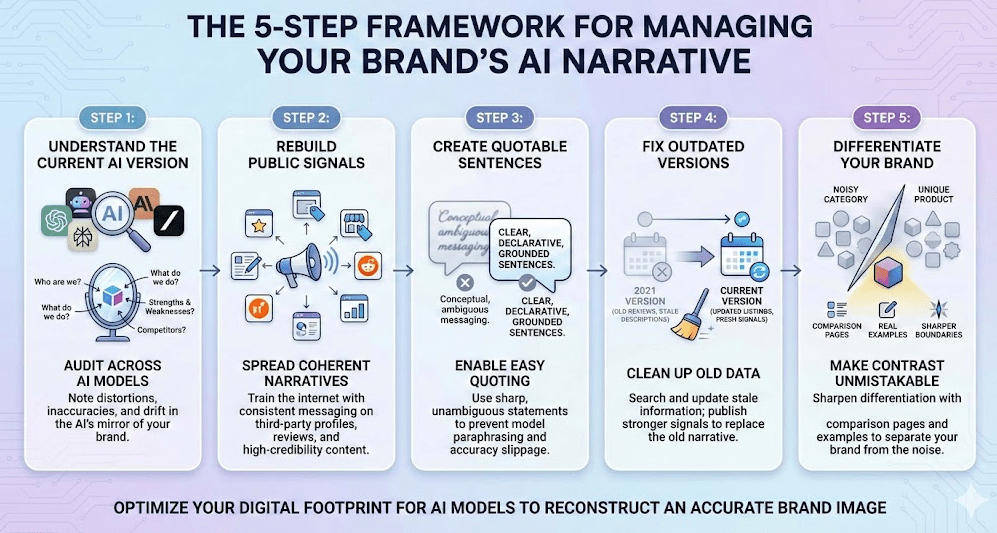
Step 2 – Rebuild The Public Signals That Models Actually Listen To
As we have discussed so far, these AI models learn from patterns – they trust repeated, persistent signals coming from multiple directions.
So instead of rewriting your website for the 15th time, try to spread coherent narratives where the model actually pays attention –
- Third-party profiles
- Marketplace listings
- Review sites
- Long form, high credibility content
- Comparison discussions
- Reddit or Hacker News threads
- Analyst write ups
When you make your narrative consistent across these surfaces, the model starts to reconstruct a more accurate version of you. Think of it less like SEO and more like training the internet.
Step 3 – Create Sentences That Are Quotable And Not Just Readable
There is a small writing trick most teams overlook.
Models often lift short, declarative sentences when describing a brand. If your messaging is poetic or conceptual, it becomes hard to quote. And when the model cannot quote you, it paraphrases you and when it paraphrases you, accuracy starts slipping.
Hence, clear, grounded sentences become super important. Any ambiguity here leads these models to start guessing which is not good for the brand.
Step 4 – Fix The Outdated Versions of You That The Internet Still Remembers
Start by searching your brand the same way a buyer would.
Go past the top results and look at older reviews, directory pages, and community threads. Anything that still describes the 2021 version of your product is a problem.
Once you spot these outdated information, clean them up wherever you have access. Update old listings, refresh stale descriptions, and add clarifications to pages you cannot edit directly. And, if something cannot be changed at the source, publish newer, stronger signals so the model has fresh material to learn from.
The goal is simple – replace the old narrative with one the internet can rediscover and the models can rebuild accurately.
Step 5 – Give The Model Ways To Differentiate You When The Category Is Noisy
Models separate clusters based on contrast. Therefore, if your differentiation is not very clear, your cluster blends into others.
Your job is to make the contrast unmistakable.
Publish comparison pages that spell out where you differ, add real examples that show how your product is used in ways others cannot match, draw sharper boundaries around your core features, and, tell stories that make your strengths obvious even to someone seeing your product for the first time.
The Real Lesson
The shift from search engines to AI assistants quietly changed a core assumption that we control our own narrative. We influence it – absolutely yes, but we no longer own it end-to-end in this new era of AI search.
AI tools reconstruct who we are based on everything the world says about us and everything the world forgets to update.
The companies that take this seriously will shape the next era of product discovery and the ones that ignore it will spend years wondering why buyers misunderstand them.
So let me leave you with a simple question – if an AI model described your product to a buyer today, would you be happy about what it answered – or be worried?
If you want to see how your brand actually shows up across AI systems, take this AI Quiz!
Frequently Asked Questions
1. Why do LLMs sometimes describe my SaaS product incorrectly?
Large language models rely on patterns found across the public internet. If your product has sparse, outdated, or inconsistent signals, the model fills gaps using nearby patterns or competitor references. This can lead to vague, generic, or entirely incorrect summaries. Improving the density and consistency of your public-facing information helps reduce these mistakes.
2. What is knowledge overshadowing and how does it affect my product’s accuracy in AI outputs?
Knowledge overshadowing occurs when models favor dominant or highly frequent patterns over less frequent ones. If a competing product has far more mentions, documentation, and third-party references, the model may prioritize that cluster of information—blending or overwriting details about your product. This is a leading cause of misclassification in crowded categories.
3. Why do outdated reviews or old feature pages still influence AI-generated descriptions?
LLMs cannot always distinguish between current and outdated information unless the recency signal is explicit. Old reviews, directory listings, and legacy content often carry strong authority signals. Because of this, models may continue using outdated narratives even after your product has evolved. Refreshing old listings and pushing updated information across credible platforms helps shift the model toward the correct version.
4. How does category overlap cause LLMs to mix up competing tools?
When multiple SaaS products share similar features or language, models struggle to separate them. In categories like CRM, CDP, and customer engagement, semantic overlap is extremely high. Without clear differentiators—such as explicit use cases, unique positioning statements, or comparison pages—the model may blend competitor attributes into your description.
5. Can improving my brand’s web presence reduce hallucinations or inaccuracies in AI search?
Yes. Research on LLM grounding shows that factual accuracy improves when models have access to richer, clearer, and more consistent external information. Increasing structured documentation, third-party references, verified profiles, and comparison content gives the model stronger grounding, reducing misinterpretations and hallucinations.
6. What steps can I take to help LLMs consistently represent my product correctly?
Start by auditing how different AI systems describe your brand. Identify inaccuracies, outdated assumptions, or competitor blending. Then strengthen your public signals: refresh old pages, create clear comparison content, update third-party listings, and publish structured, high-clarity explanations of your product. These signals help LLMs form a more accurate and consistent mental model of your offering.





Leave a comment